Gb Locrian
G flat Locrian scale for guitar.
The Gb Locrian is a seven-note scale, it is also called a mode. Colored circles in the diagram mark the notes in the scale (darker color highlighting the root notes). In the fretboard pattern, the first root note is on the 6th string, 2nd fret.
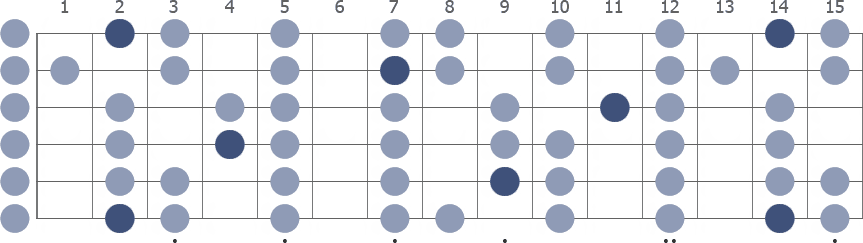
Gb Locrian 2 octaves
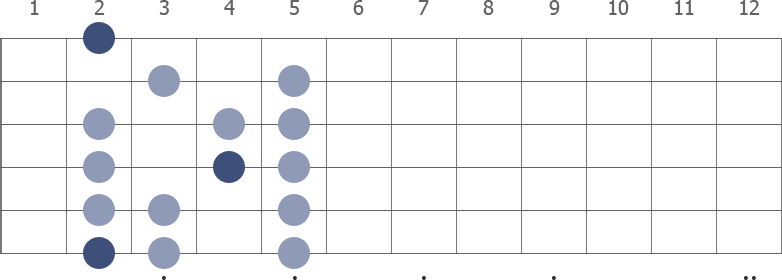
Gb Locrian full fretboard
Gb Locrian note names
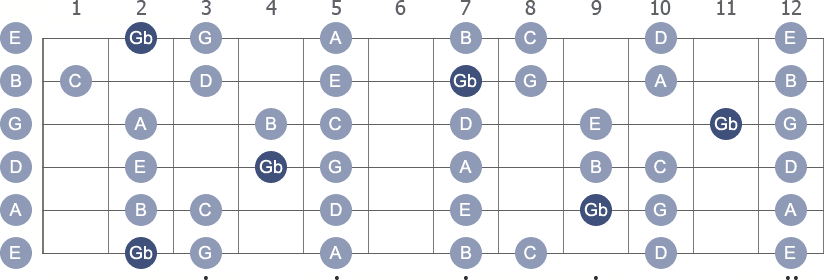
The scale displayed with its numeric formula, notes, intervals and scale degrees.
| Formula | Notes | Intervals | Degrees |
|---|---|---|---|
| 1 | Gb | Unison | Tonic |
| b2 | Abb | Minor second | Supertonic |
| b3 | Bbb | Minor third | Mediant |
| 4 | Cb | Perfect fourth | Subdominant |
| b5 | Dbb | Diminished fifth | Dominant |
| b6 | Ebb | Minor sixth | Submediant |
| b7 | Fb | Minor seventh | Subtonic |
The second degree is written as Abb, which is the same as G. The third degree is written as BBb, which is the same as A. The fourth degree is written as Cb, which is the same as B. The fifth degree is written as Dbb, which is the same as C. The sixth degree is written as Ebb, which is the same as D. The seventh degree is written as Fb, which is the same as E. A practice in a scale notation is to not include the same letter twice, if it can be avoided.
The G flat Locrian scale consists of seven notes. These can be described as steps on the guitar fingerboard according to the following formula: half, whole, whole, half, whole, whole, whole from the first note to the same in the next octave.
The Gb Locrian is a mode of the G Major Scale. It contains exactly the same notes, but starts on another note.
This scale is primarily used in jazz and is rare in popular music.
One way to learn this scale is to think of it as the G Major starting from its seventh note. Another way is to think of it as the Gb Phrygian with a flattened 5th.
Chords that are related to this scale are the following:
| Gbdim, Gbm7b5 |
| G, Gmaj7, G6, G6/9, Gmaj9, Gmaj13 |
| Am, Am7, Am6, Am9, Am11, Am13 |
| Bm, Bm7 |
| C, Cmaj7, C6, C6/9, Cmaj9, Cmaj13 |
| D, D7, D6, D6/9, D9, D11, D13 |
| Em, Em7, Em9, Em11 |
The tones in these chords correspond to the tones of the Gb Locrian scale.
Related to Locrian are Locrian ♮2 and Locrian #6, being the 4th mode of the Melodic Minor and the 2nd mode of the Harmonic Minor.
The Gb Locrian ♮2 scale, also called Gb Half-diminished scale, is identical with the Gb Locrian except for a major second instead of a minor second which is indicated by the natural symbol. It can be displayed as follows:
| Formula | Notes | Intervals | Degrees |
|---|---|---|---|
| 1 | Gb | Unison | Tonic |
| 2 | Ab | Major second | Supertonic |
| b3 | Bbb | Minor third | Mediant |
| 4 | Cb | Perfect fourth | Subdominant |
| b5 | Dbb | Diminished fifth | Dominant |
| b6 | Ebb | Minor sixth | Submediant |
| b7 | Fb | Minor seventh | Subtonic |
The Gb Locrian ♮2 contains the same notes as the A Melodic Minor Scale, but starts on another note.
The Gb Locrian #6 scale is identical with the Gb Locrian except for a major sixth instead of a minor sixth which is indicated by the sharp symbol in the name. It can be displayed as follows:
| Formula | Notes | Intervals | Degrees |
|---|---|---|---|
| 1 | Gb | Unison | Tonic |
| b2 | Abb | Minor second | Supertonic |
| b3 | Bbb | Minor third | Mediant |
| 4 | Cb | Perfect fourth | Subdominant |
| b5 | Dbb | Diminished fifth | Dominant |
| 6 | Eb | Major sixth | Submediant |
| b7 | Fb | Minor seventh | Subtonic |
The Gb Locrian #6 contains the same notes as the E Harmonic Minor Scale, but starts on another note.