Eb Pentatonic Minor
Ebm Pentatonic scale for guitar.
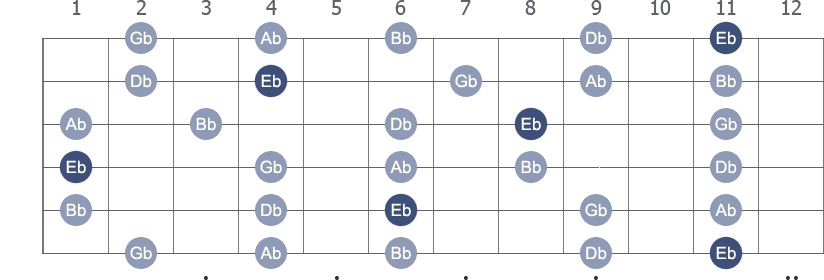
The E flat Pentatonic Minor is a five-note scale. The diagram shows a fingerboard with the notes in the scale. Darker color marks the root notes. In the two-octave pattern, the first root note is on the 6th string, 11th fret.
Eb Pentatonic Minor 2 octaves
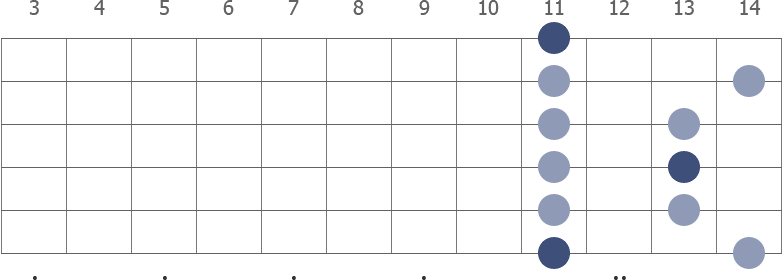
Eb Pentatonic Minor full fretboard
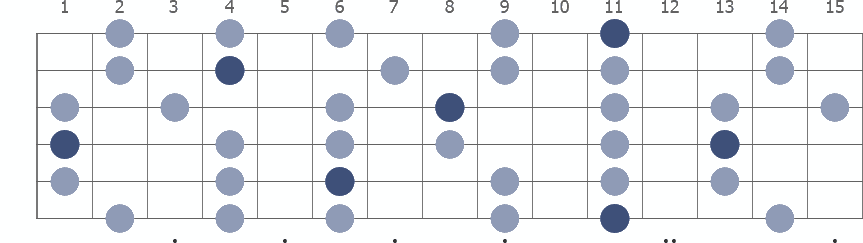
Eb Pentatonic Minor with note names
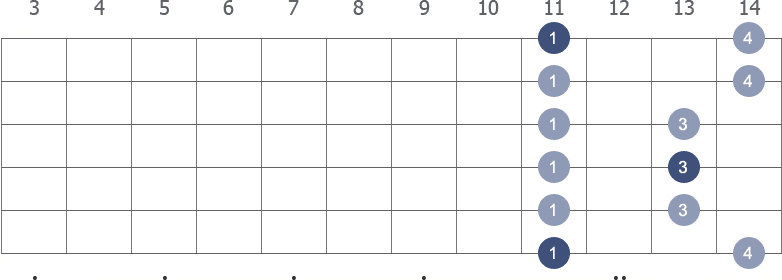
Shape 1 (11th position) with fingerings
Shape 2 (1st position) with fingerings
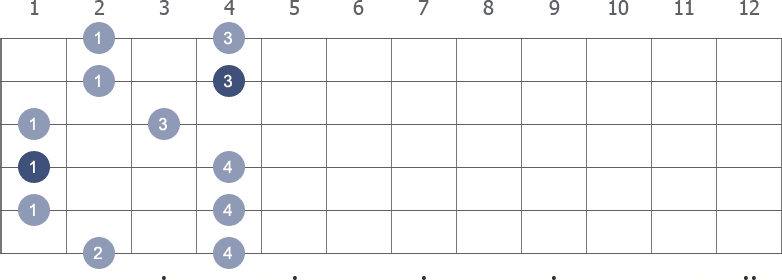
Shape 3 (3rd position) with fingerings
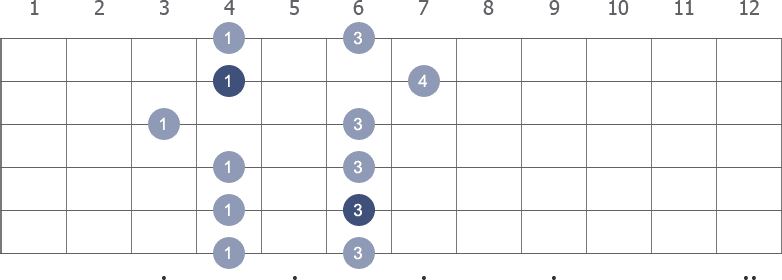
Shape 4 (6th position) with fingerings
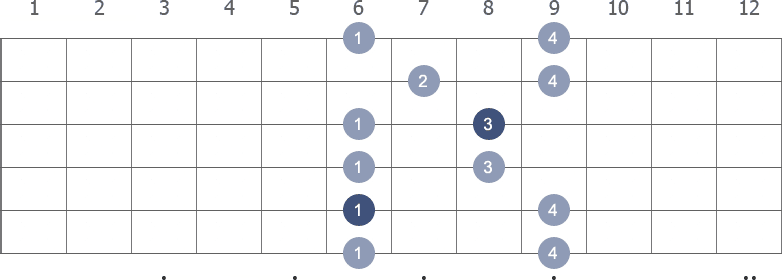
Shape 5 (8th position) with fingerings
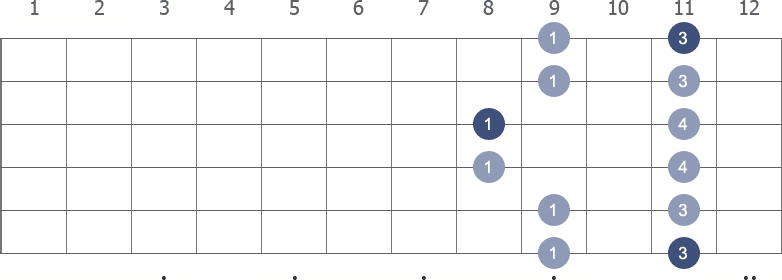
The scale and its scale degrees.
| Formula | Notes |
|---|---|
| 1 | Eb |
| b3 | Gb |
| 4 | Ab |
| 5 | Bb |
| b7 | Db |
The second and the sixth degrees are omitted, for the reason that the degrees are based on the natural Minor seven-note scale.
The interval formula (3 - 2 - 2 - 3 - 2) can be expound into specific notes of the scale.
| Notes (ascending) | Interval |
|---|---|
| Eb-Gb | m3 |
| Eb-Ab | P4 |
| Eb-Bb | P5 |
| Eb-Db | m7 |
Abbreviations are used: M / m stands for major / minor and P stands for perfect.
| Notes (descending) | Interval |
|---|---|
| Eb-Db | M2 |
| Eb-Bb | P4 |
| Eb-Ab | P5 |
| Eb-Gb | M6 |
The notes in the scale can be described as intervals, written as 3 - 2 - 2 - 3 - 2 from the first note to the first in next octave.
The Eb Pentatonic Minor is relative to Gb Pentatonic Major. Both scales include the same notes but has different root notes.
This scale is one of the most common for guitarists and utilized in conjunction with lots of styles, including pop, rock and blues.
The easiest way to learn this scale is probably to think of it as the Eb Minor scale without the second and the sixth degrees.
Some of the chords that are related to this scale are listed here:
- Ebm
- Gb
- Abm7
- Bbm7
- Db5
The tones in these chords correspond to the tones of the Eb Pentatonic Minor scale. Note that the match is not completely exact, the third (B) in Abm7 and the fifth (F) in Bbm7 are not included in the scale.
Related to this scale is the Eb Pentatonic Minor add2, adding the 2nd degree. It can be displayed as follows:
| Formula | Notes | Intervals | Degrees |
|---|---|---|---|
| 1 | Eb | Unison | Tonic |
| 2 | F | Major second | Supertonic |
| b3 | Gb | Minor third | Mediant |
| 4 | Ab | Perfect fourth | Subdominant |
| 5 | Bb | Perfect fifth | Dominant |
| b7 | Db | Minor seventh | Subtonic |
The Eb Pentatonic Minor add2 scale, is identical with the Eb Minor except for missing the major 6th interval.
E flat Pentatonic Minor scale first shape ascending.

The numbers above the tablature are suggested fingerings.